
Depuis la sortie de ChatGPT par OpenAI en fin 2022, l’Intelligence Artificielle nourrit les conversations professionnelles dans tous les secteurs. Ayant pas mal joué avec l’IA en tant qu’auteur-informaticien, je vous propose ce petit tour d’horizon des usages de l’IA dans les métiers du livre.
1. Pour générer des illustrations
L’IA générative permet de produire très simplement des illustrations. Dès la sortie des premiers modèles gratuits (comme Dall-e ou MidJourney), des questions légitimes se sont posées :
- Quid de la propriété intellectuelle de la base d’apprentissage ? (a priori construite sans le consentement des ayants droits) : plusieurs procès sont en cours envers OpenAI sur ce sujet. Des solutions plus récentes et plus éthiques (comme Claude d’Anthropic) affirment construire des données d’entrainement dans le respect des droits d’auteurs. Maintenant que l‘IA Act est voté en Europe, les entreprises d’IA doivent s’y conformer. Ce texte parle du droit d’auteur, une exigence évidente et vitale. Cela inclut l’adhésion aux clauses d’opt-out, permettant aux détenteurs de droits de refuser l’utilisation de leur contenu par les systèmes d’IA. Voir sur ce sujet une analyse technique sur l’empoisonnement de l’apprentissage des moteurs d’IA afin de protéger le style graphique)
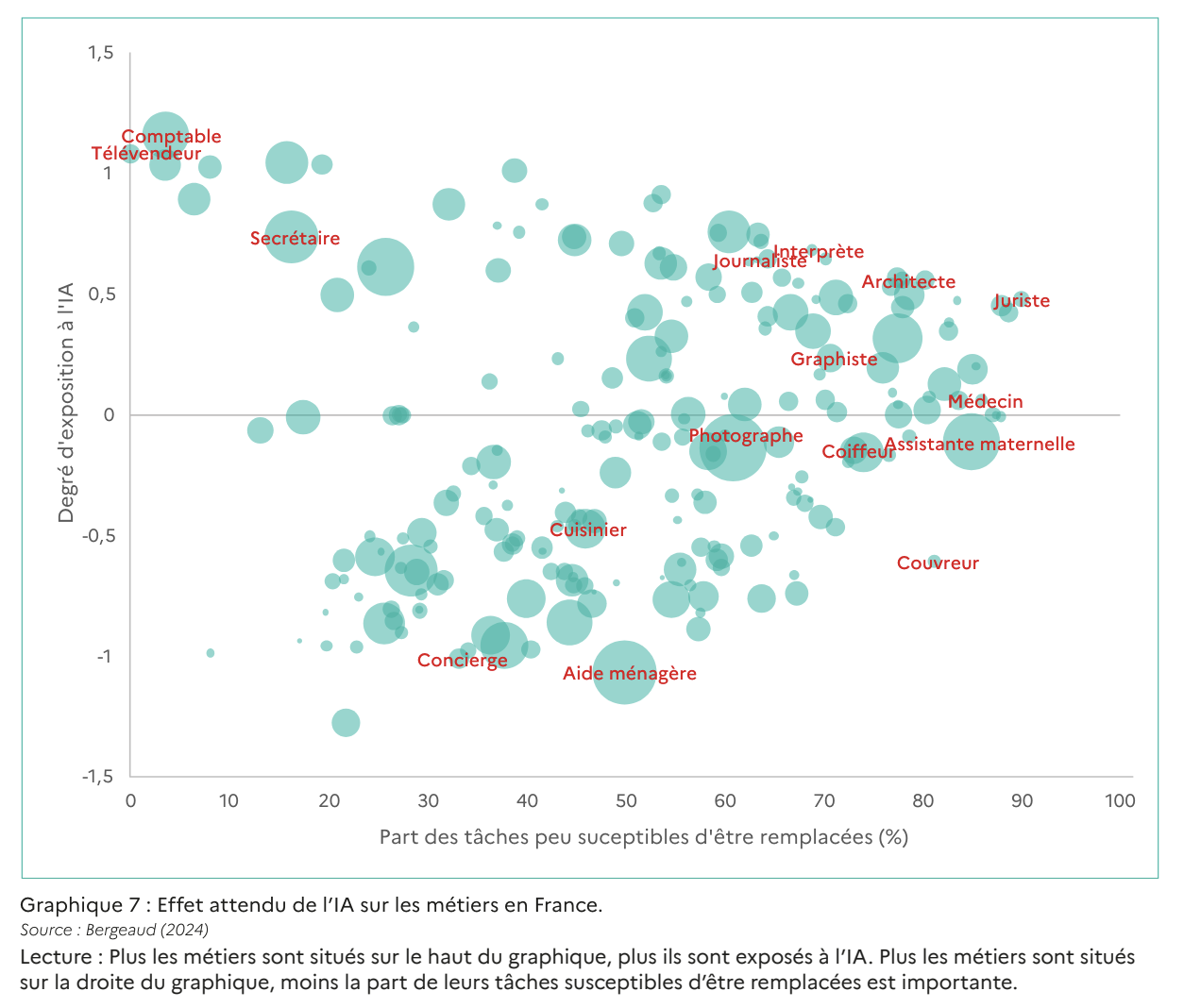
- Quid de la pérennité de l’emploi des graphistes utilisés par les maisons d’édition ? Cette question se pose évidemment pour nombre de métiers (dont les traducteurs – voir plus bas). Le rapport de la commission France sur l’IA y répond partiellement ici au chapitre 1.4 (l’IA : créatrice ou destructrice d’emplois ?). La figure ci-dessous, montre que le métier de graphiste, même s’il est exposé à l’IA, ne fait pas partie des emplois les plus menacés.
- Quid de la perte de diversité dans les types d’illustrations ? Au début, nous nous sommes tous émerveillés par les possibilités graphiques offertes par l’IA Générative. Maintenant, nous sommes tous un peu blasé par ce style trop reconnaissable. La « patte » d’un bon graphiste ne sera pas si facilement remplaçable…

2. Pour la traduction « automatique »
Les traducteurs techniques sont sans doute les plus touchés à ce jour. L’apparition d’offres gratuites comme DeepL ou Google Translate ont permis à des employés d’être autonomes dans la traduction professionnelle « de tous les jours ». Mais qu’en est-il pour les traducteurs littéraires ?
Dans les maisons d’éditions, une certaine opacité règne sur le sujet. Le risque, à terme, est de transformer la mission : passer de traducteur (droit d’auteur) à correcteur d’une version traduite automatiquement (payé à la tache), ce qui impliquerait des revenus plus bas et moins de missions (plus besoin de traduction humaine pour les livres de cuisine par exemple). Un article du journal Le Monde décrit bien la situation actuelle. Atlas, l’association pour la promotion de la traduction littéraire, considère ouvertement l’IAG (IA Générative) comme néfaste et a écrit une tribune ici.
Le collectif « en chair et en os » lance un appel à témoignages pour signaler les abus dans ce domaine des IA générative.
A noter que des maisons d’éditions peuvent désormais rédiger rapidement des fiches descriptives de romans dans plusieurs langues afin de mieux approcher leurs collègues étrangers. Cette première étape (qui nécessitera tout de même une traduction humaine, si l’affaire se conclut), permet d’augmenter les chances d’une cession.
3. Pour la sélection/classification des manuscrits
Un des domaines phares de l’Intelligence Artificielle (et notamment le Machine Learning – apprentissage supervisé) est la classification. A partir d’un corpus de référence, où l’algorithme apprend à classer des objets dans différentes catégories, il est ensuite capable de prédire dans quelle catégorie sera classé un nouvel élément.
Je me suis amusé à écrire un tel programme (python/scikit learn). Mon corpus contient 1234 extraits (environ 50 pages chacun) de 210 romans de 135 auteurs/autrices différents. Chacun de ces extraits est analysé sous 28 critères (dimensions) : nombre de virgules par phrase, % de verbe au passé, % de « je » comme sujet, longueur moyenne des phrases, etc. Une analyse essentiellement syntaxique, et très peu sémantique.
Je lui précise également pour chaque extrait son genre (Blanche, SF, Polar, Fantasy, Romance) et son type (classique du XIXe, classique du XXe, best seller, Goncourt, Nobel …).
Ces 28 paramètres * 1234 extraits sont ensuite appris par un réseau neuronal (100 couches de neurones, de type MLPClassifier de scikit-learn).
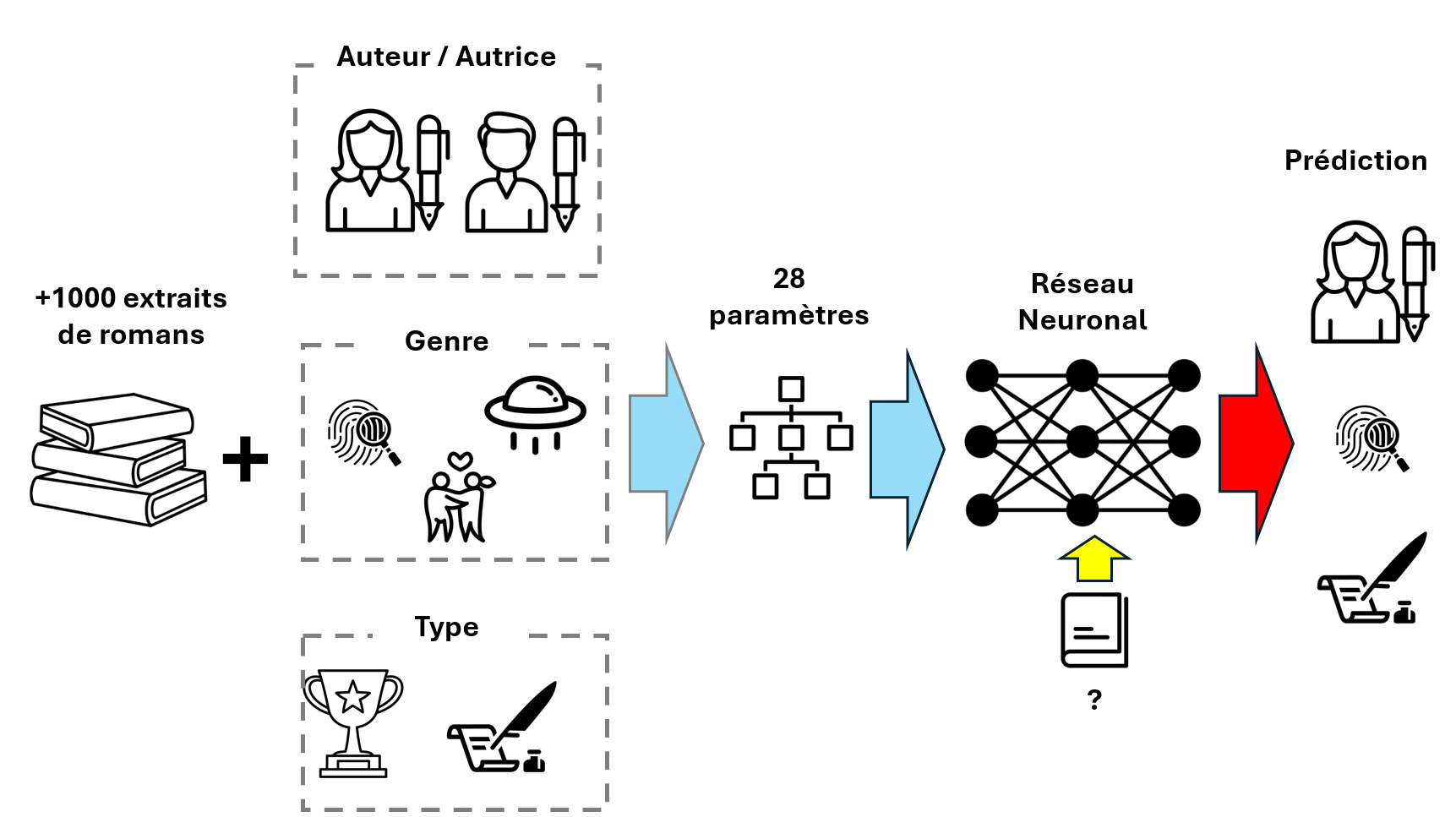
Ensuite, je lui propose des extraits inédits de romans qu’il ne connait pas. L’objectif est qu’il arrive à deviner l’auteur, mais aussi le genre et le type du roman. En gros, je lui demande de retrouver l’auteur sans vraiment lire ou comprendre le texte, seulement avec des paramètres structurants qui caractérisent son écriture (un peu comme si vous arriviez à identifier une personne uniquement par sa façon de marcher – et non pas par sa voix ou son visage).
Les résultats sont impressionnants : il retrouve les bonnes informations dans plus de 80% des cas.

- La première colonne « status » indique si la prédiction de l’auteur/autrice est correcte (OK/NOK).
- La seconde colonne donne le nom deviné. Même quand le logiciel se trompe, il est amusant de voir qu’il reste dans un style proche : Guillaume Musso vs Joel Dicker, Virginie Grimaldi vs Melissa Da Costa, Greg Egan vs Philip K Dick.
- Le troisième colonne donne le % de confiance à cette prédiction.
- La quatrième colonne donne le genre deviné. Là encore, et suivant l’auteur/autrice, il y a un flou légitime entre YA, Blanche ou Romance.
- La dernière colonne donne le type deviné. Après avoir « ingéré » le tome 1 d’Harry Potter, le système reconnait que le tome 3 est potentiellement un « best seller » (ce qui n’est pas le cas d’un de mes romans non publié que je lui ai soumis ! 😜).
Un tel logiciel, s’il était perfectionné, pourrait servir à :
- Détecter les prêtes plumes, ou caractériser les changements de style d’un auteur dans le temps (par exemple lors de l’analyse des nombreux Balzac ou San Antonio existants)
- Filtrer les manuscrits reçus pour « détecter » des ressemblances avec un auteur/autrice existant, ou pourquoi pas, détecter des futurs best-seller ? (Ah si les éditeurs qui ont refusé JK Rowling avaient eu ce logiciel ! 😂).
- Analyser le marché pour comprendre les tendances. Ajouter les chiffres de ventes dans le modèle d’apprentissage, etc. Faire un vrai boulot de « data scientist » pour mieux comprendre le marché et les goûts des lecteurs/lectrices.
Une des possibilités, et sans doute aussi un des risques, est de faire du « design to sell » ou du « design to prize« . Construire des romans sur « cahier des charges » pour qu’ils deviennent des best-sellers ou gagnent des prix. (Mais je suis sans doute un peu naïf, cela doit exister d’une façon ou d’une autre. 😏)
Une autre façon de faire, serait d’utiliser le clustering : une forme d’apprentissage non-supervisé, où l’IA regrouperait toute seule les auteurs/autrices en fonction de critères qu’elle jugerait pertinent. Là encore, il serait amusant de voir les rapprochements qu’elle ferait. De qui Mathias Enard est-il le plus proche : de Balzac ou de Stendhal ? Les 95 romans de Balzac sont-ils dans le même cluster ? C’est le genre de questions auxquelles je vais bientôt m’atteler ! 🤓
4. Pour l’aide à la documentation
L’IA générative (chatGPT) peut aider un romancier dans ses phases de recherche et de documentation sur un sujet bien précis. C’est une excellente alternative à Wikipédia si le prompt est bien choisi. On peut demander « explique moi un concept comme si j’étais un enfant de 8 ans ». Bien entendu, il ne faudra pas copier tel quelle la réponse, mais la vulgarisation choisie par l’IA sera intéressante à analyser. Pour la Trilogie Baryonique, j’ai utilisé de tel prompt pour, par exemple, trouver une idée pour expliquer simplement la polarisation de la lumière.
5. Pour l’aide au scénario
Intrinsèquement, ce n’est pas une bonne idée que de s’appuyer sur une IA générative pour écrire un scénario ou un synopsis. Tout simplement car l’IA générative a appris sur un très large corpus, mais, dans un contexte donné, va choisir les réponses les plus probables.
Voir l’exemple ci-dessous (extrait de la commission sur l’IA sus-mentionnée) : dans un contexte géopolitique, le mot suivant le plus probable était « pays ». Peut-être que dans un contexte économique, l’IA aurait alors choisi « acteur ». Dans un contexte « COVID », « foyer » puis « infection ».

On comprend aisément pourquoi, quand on souhaite « inventer » une histoire, cette approche probabiliste est néfaste. L’IA va nous ressortir en premier les clichés, et les ressorts les plus communément vus. Que pensez-vous de la réponse ci-dessous ? Un air de « déja-vu », non ? 😉

6. Pour aider à l’écriture de romans
Il y a plusieurs 3 types de collaboration humain/IA :
- La substitution : l’IA remplace l’humain. Le roman est écrit par une IA. C’est possible actuellement, mais pour les raisons évoquées au point précédent, le résultat n’est pas terrible. Se souvenir également que les IA génératives sont « neutres », censurés au nom de la morale et de l’éthique sur ce qu’elles peuvent écrire. Le résultat risque d’être insipide, fade, et très ressemblant d’un texte à l’autre (le même syndrome que pour les images). Imaginez-vous une scène d’ivresse entre un homme et une femme raconté à la mode Bukowski ? (demandez-donc à chatGPT 🤪.)
- La collaboration : l’IA écrit un premier jet, l’humain corrige. Chacun fait ce qu’il sait le mieux faire et les deux collaborent ensemble. On doit pouvoir trouver des cas qui fonctionnent : description d’un lieu si manque d’inspiration, génération de patronymes, aide à la documentation, etc.
- L’augmentation : 1+1 = 3 : l’IA est vu comme un outil qui augmente la productivité / créativité / style / … de l’humain. A ce stade, l’augmentation existe dans pas mal de métiers (par exemple le développement informatique), mais je ne vois guère d’application pour le métier d’écrivain.
Comme vu au point 3, l’IA peut également être utilisé pour faire du « Design to Prize ». Après avoir analysé tous les prix Goncourt (ou autre), l’IA est capable d’en comprendre les « patterns » (recettes de fabrication) et évalue mon travail sous cet angle pour, petit à petit, converger vers un écrit « gouncourisable ». C’est à ce jour réaliste. Pour l’anecdote, je m’étais servi d’une approche similaire (voir analyse des romans) pour participer au concours « San Antonio » (et imiter le style de l’auteur) : mon roman avait terminé deuxième du concours. Le radar ci-dessous compare le modèle original pris (en bleu) et mon texte (en orange).

7. La promotion du livre
Pour les auteurs/autrices qui ne bénéficieraient pas de la promotion d’une maison d’édition, l’IA générative offre plein de services pour aider à mieux communiquer sur les réseaux sociaux, à faire des visuels (⚠️ voir point 1 : les illustrations sont un sujet sensible dans la profession), etc.
On peut même imaginer (à court terme) que les progrès des deepfakes permettent d’enregistrer des interviews d’auteur/autrice sans leur présence. Les technologies modernes permettent d’imiter parfaitement la voix ou le visage d’une personne.
8. Pour les libraires (et les bibliothécaires !)
Lors des 7eme rencontres nationales de la librairie française (en juin 2024), André Ourednik a discuté de la question : « qu’est-ce que l’intelligence artificielle va faire aux livres et aux librairies ? »
Dans la vidéo, il revient sur les algorithmes de proposition de livres basés sur l’IA (et des dangers de suivre des recommandations d’algorithmes construits sur d’autres valeurs sociétales que la nôtre). En fin de présentation, il donne quelques pistes pour ne pas faire le jeu de ces algos mortifères, et revendique l’opt-out : c’est à dire « considérer l’IA comme une opportunité de se profiler comme une entreprise qui permet de s’en passer. En tant que libraire, être fier de respecter la vie privée de ses clients, de ne pas vendre leur données d’usage, de les considérer comme sujets d’une vraie relation sociale, plutôt que comme des objets quantifiables.«
Conclusion
Voilà un rapide tour d’horizon de quelques usages possibles de l’IA dans le monde de l’édition. J’en oublie forcément plein, mais cela peut donner quelques idées. Vos commentaires sont les bienvenus !

Bonjour,
L’article aborde des sujets qui me passionnent — l’IA et l’écriture — mais je souhaite exprimer mon désaccord sur plusieurs points.
Concernant le graphique présenté, je pense qu’il sous-estime beaucoup l’impact de l’IA dans certains domaines. L’IA excelle dans les prévisions et le traitement des connaissances formelles, ce qui rend des professions comme interprète, juriste ou médecin partiellement remplaçables.
Pour les interprètes, les progrès récents en IA sont remarquables. Les systèmes actuels comprennent le sens, le contexte et les nuances bien mieux que par le passé. Certes, la supervision humaine reste nécessaire, mais l’évolution rapide de la technologie inquiète déjà de nombreux professionnels. Certains indépendants rapportent une baisse de 40 à 60 % de leurs revenus, leur rôle évoluant vers celui de vérificateur de traductions automatisées.
Concernant les limitations, la confidentialité et souvent évoquée, mais de plus en plus d’alternatives fonctionnant sur un ordinateur personnel (avec une carte graphique équipée d’au moins 10 Go de Ram). (pinokio : https://pinokio.computer, lm studio : https://lmstudio.ai)
Quant aux juristes, l’IA surpasse déjà l’humain dans la mémorisation des lois et des jurisprudences. Bien que l’automatisation complète de la justice ne soit pas envisageable, l’IA pourrait révolutionner de nombreux aspects du travail juridique.
Mettre au même niveau les coiffeurs et assistants maternels est presque choquant (il n’y a pire aveugle que celui qui ne veut pas voir)
Dans le domaine médical, l’automatisation de certaines tâches présenterait de grands avantages. L’IA peut surpasser les humains dans la connaissance des maladies, des symptômes et des interactions médicamenteuses. Elle pourrait être utilisée pour les diagnostics préliminaires ou le tri aux urgences, toujours sous supervision humaine. Et contrairement à internet elle va au plus probable et non au plus grave.
Ensuite je ne suis pas d’accord sur la perte de créativité dans la génération d’image. Les dernières évolutions permettent de dessiner un brouillon et de donner un style. On peut même « composer » l’image (https://x.com/dr_cintas/status/1761060705686491263)
En fait ce qui est généralement sous-estimé dans l’IA c’est les réseaux de neurones, ils peuvent créer des comportements inattendus. Par exemple, faire jouer un LLM aux échecs, des chercheurs se sont rendu compte qu’un moteur de langage pouvait, pour s’adapter, se créer « une image mentale » du plateau de jeu ! alors qu’il n’est pas du tout conçu pour cela. (vidéo sur YouTube : ChatGPT rêve-t-il de cavaliers électriques ? : https://www.youtube.com/watch?v=6D1XIbkm4JE)
Pour l’écriture j’ai essayé, j’ai effectivement été très déçu par la création de contenu « original ». Par contre pour l’analyse d’un texte, la reformulation d’une phrase, la création de résumés ou de pitchs, la documentation, c’est très pratique.
Pour aider l’écrivain, je suis persuadé que la collaboration et l’augmentation sont possibles ou le seront à court terme. Mais pour avoir essayé, ce serait plutôt l’humain qui écrit (ou dicte) et l’IA qui corrige.
De mon côté je préfère Claude à Chat GPT, et pour les recherches Perplexity à Google
Je viens d’écouter votre livre (La tragédie de l’orque), j’aime beaucoup. Vivement la suite. De la science-fiction basée sur de la science !
(reformulé partiellement par Claude 😉 )
Merci KaT pour ce commentaire argumenté ! Claude est aussi mon ami 😉