Je continue mon étude des romans au travers de leur style littéraire. Grâce à 19 points de mesures très simples (comme la longueur des phrases, le taux de verbe au présent, l’utilisation de la ponctuation, la richesse lexicale, etc.), j’utilise des algorithmes de machine learning pour cartographier ces oeuvres. L’idée est de voir si, sans tenir compte du fond (l’analyse sémantique), on peut reconnaître l’auteur ou deviner son genre littéraire (polar, SF, classique, contemporain…)
C’est un exercice délicat car chaque roman est a priori différent et l’espace d’étude est à 19 dimensions – difficile à visualiser ou analyser. Une technique utilisée dans ce cas est la réduction de dimensionnalité, via une analyse en composante principale.
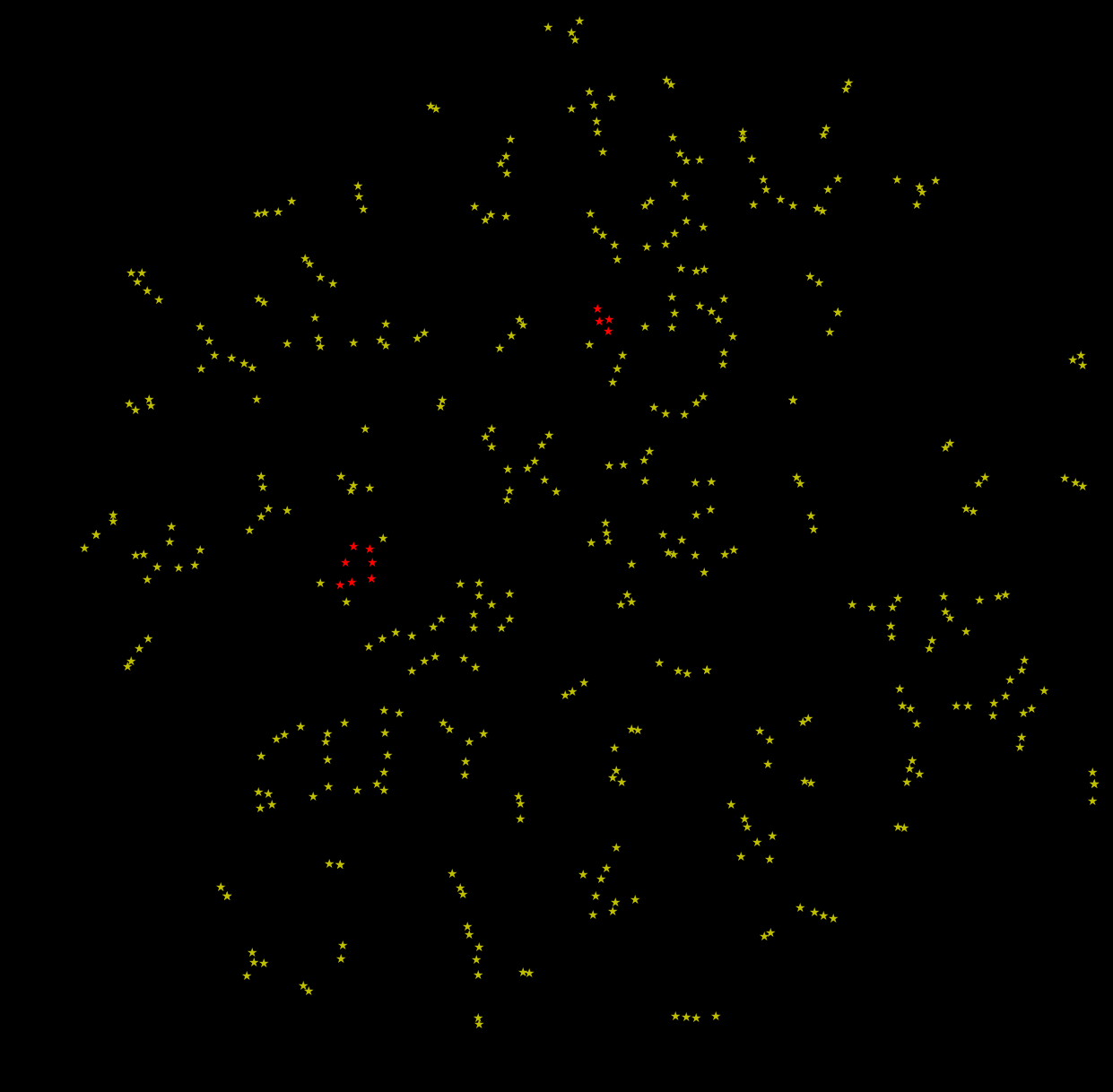
L’image ci-dessus n’est pas une photo du ciel, mais la représentation en 2 dimensions de 200 romans classiques ou contemporains générée en utilisant l’algorithme t-SNE (t-distributed stochastic neighbor embedding). Attention ! Il n’y a pas de signification claire aux deux axes : ils représentent les meilleures combinaisons linéaires des critères pour les regrouper de façon pertinente.
On y retrouve quelques points intéressants que je détaille ci-dessous.
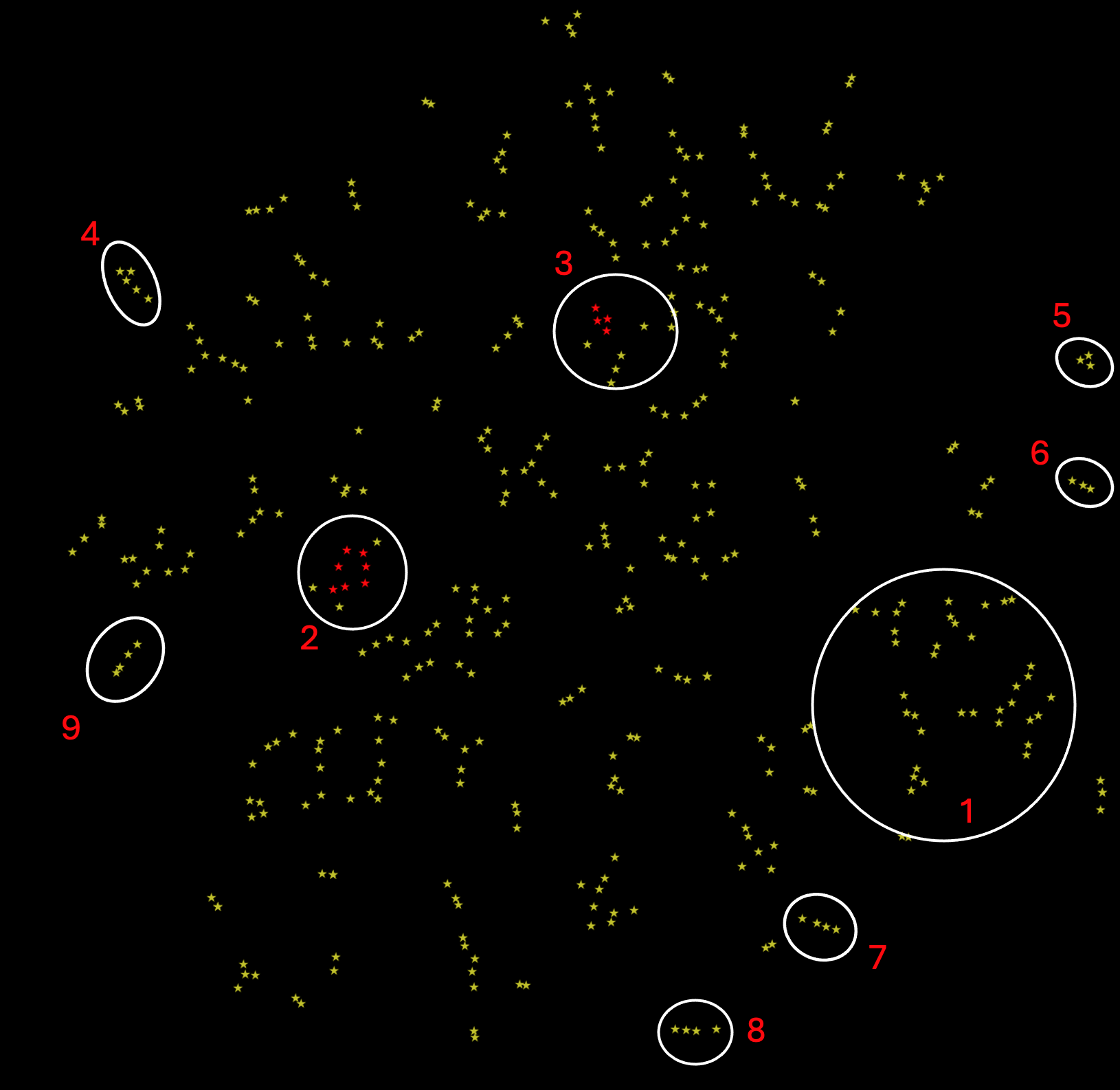
- Les classiques sont majoritairement ici: Hugo, Balzac, Tolstoï, Flaubert, …
- Mes premiers romans dit « époque vallée de Chantebrie » sont regroupés ici – ainsi que celui en cours d’écriture (sortie RL26)
- Mes romans de Science-Fiction (La trilogie baryonique et Octomes à paraître en octobre 25) se trouvent ailleurs, avec d’autres romans de SF de Jack Vance, Greg Egan ou Laurent Genefort. Visiblement, la SF se reconnaît au style et rythme de l’écriture 😉
- San-Antonio et son style reconnaissable forme un ilot à part
- Idem pour Patrick Rambaud
- Idem pour René Fallet
- Idem pour Michel Houellebecq (à proximité de Marguerite Yourcenar et Simone de Beauvoir – quand on dit que cet auteur mérite le Nobel 😉)
- Idem pour Jorge Luis Borges (❤️)
- Ici, un exemple d’alignement de 4 excellents romans de littérature contemporaine : Sandrine Collette (On était des loups), Virginie Despentes (Cher connard) et Emma Becker (L’inconduite, Le mal joli)
Que retenir de tout ça ?
Pas grand chose, si n’est que je trouve cette voie lactée littéraire très jolie. A titre personnel, je n’ai pas écrit la SF comme les autres romans, et je suis satisfait de constater que cela se voit aussi nettement sur cette représentation.
Il y aurait mille autres représentations à faire à partir de ces données. On pourrait vérifier si les époques sont visibles, les genres littéraires, pourquoi pas également le genre des auteurs/autrices (spoiler, non), tenter de voir si les succès en librairies se devinent… Bref le monde des data science est vertigineux 😜

Laisser un commentaire